
データベース型サイトのSEO対策!基本から具体的な施策まで解説

データベース型サイトのSEOで成果が出ずに悩んでいませんか。ECサイト、求人サイト、不動産サイト、グルメサイトなど、データベースから自動生成された数万〜数億のページを抱えるサイトでは、記事を1本ずつ磨くような従来のSEO手法はまったく通用しません。1ページの改善ではなく、テンプレートとサイト構造そのものを最適化しなければ、検索順位は1ミリも動かないのがこの領域の現実です。
本記事では、データベース型サイトのSEOで上位表示を実現するために必要な考え方を、5ステップの改善プロセスと、4ファネル(クロール/インデックス/PLP/順位)ごとの具体施策14選として体系化して解説します。さらに、2026年にインパクトが拡大しているLLMO(生成AI最適化)、E-E-A-T、Core Web Vitals(INPを含む)、構造化データ、ファセット検索の制御といった最新論点までを一気通貫でカバーしました。
大規模なデータベース型サイトを伸ばしたいSEO担当者の方、開発と一緒にテクニカルSEOを進めたい方、何から手を付けるか優先順位に迷っている方にとって、明日から実行できる施策が見つかる構成にしています。
■この記事で得られること
- データベース型サイトのSEOが「1ページ単位」ではなく「ファネル×キーワードカテゴリ」で改善する理由
- 上位表示までの5ステップ改善プロセス(現状把握→課題特定→施策実行→効果測定→横展開)
- クロール・インデックス・PLP一致・順位向上の4ファネルごとの具体施策14選
- 2026年に重要度を増したLLMO(生成AI最適化)/ Core Web Vitals / 構造化データの対応方針
- データベース型サイト特有の重複コンテンツ・ファセット検索・動的URLの制御方法
📺 動画でも解説しています(約16分)


データベース型サイトとは
データベース型サイトとは、データベースに格納された情報をテンプレートに流し込んで、大量のWEBページを自動生成するサイト形式のことです。情報をデータベースで管理・参照していることから、ユーザーがブラウザ上で格納データを検索できます。
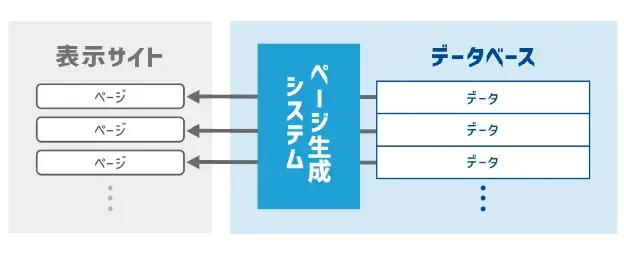
データベース型のサイトは、膨大なデータに対応しやすい構造となります。テンプレートを活用し、ページ生成も自動で行えることから、網羅すべきデータやページ量が多くなる大規模タイプのサイトに採用されることが多いです。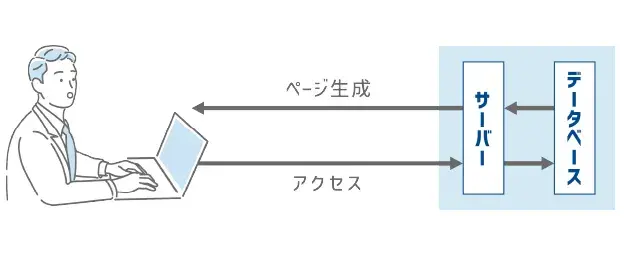
ECサイト、求人サイト、不動産サイトなどが代表的ですが、旅行サイト、ホテルサイト、グルメサイト、レシピサイト、美容サイトなど大量の情報を扱うサイトであればデータベース型サイトであることが多く、口コミサイトやUGCサイトなどでもデータベース型を採用していることがほとんどです。
※UGC(User Generated Contents):ユーザーが作成したコンテンツのこと。Yahoo!知恵袋や掲示板のようにユーザーが投稿することでコンテンツとして成立し、データベースに格納することでページの大量生産を可能にしています。
なお、WordPressのようなCMSで作られたWEBサイトでもデータベースを利用していますが、CMSの場合はサイトの構築にデータベースを使っているだけであり、コンテンツにはデータベースを利用していないためデータベース型サイトとは呼びません。
記事を1本ずつ手作業で書く記事型メディアとは、設計思想もSEO手法も根本から異なります。
両者の違いを下表で整理します。
| 比較項目 | データベース型サイト | 記事型サイト |
|---|---|---|
| ページ生成 | データベース×テンプレートで自動生成 | 1ページずつ手動で執筆 |
| ページ数 | 数万〜数億ページ | 数百〜数千ページ |
| SEO改善単位 | ページテンプレート単位 | 個別ページ単位 |
| 主要施策 | テクニカルSEO(クロール/インデックス/構造化) | コンテンツSEO(記事品質) |
| 対策キーワード | ロングテール一括取得 | メイン→ロングテールへ拡張 |
| 主な評価指標 | インデックス率・PLP一致率・テンプレ順位 | 記事順位・滞在時間・PV |
データベース型サイトでは、1ページずつ磨くという発想が通用しません。「テンプレートを直せば数十万ページが一気に改善する」「逆にテンプレートが歪めばサイト全体が沈む」という性質を持つため、サイト構造そのものをSEO最適化する技術が問われます。
データベース型サイトの例
| 種類 | 事例 | おおよそのページ数 |
|---|---|---|
| ECサイト | Amazon、楽天市場、Yahoo!ショッピング | 1,000万〜数千万 |
| 求人サイト | Indeed、マイナビ、リクナビ、doda | 600万〜5,000万超 |
| 不動産サイト | SUUMO、LIFULL HOME’S、at home | 800万〜1,000万超 |
| 旅行/ホテル | 楽天トラベル、じゃらん、Booking.com、Expedia | 数百万〜数千万 |
| グルメ | 食べログ、ぐるなび、Retty | 1,000万〜7,000万 |
| レシピ | クックパッド、Nadia | 数百万 |
| 美容 | ホットペッパービューティー、ミニモ | 数百万 |
| CGM/口コミ | OpenWork、転職会議、Quora、Reddit | 数千万〜数億 |
例として、Amazonは数千万ページを抱えますが、商品ページ・カテゴリページ・レビューページが整然と一定フォーマットで揃っています。情報の粒度が揃っていることが、データベース型サイトがSEOで圧倒的に強い理由です。
なお、WordPressのようなCMSもデータベースを利用していますが、ページ生成にデータベースを使っているわけではないため、データベース型サイトには該当しません。
データベース型サイトのサイト構造
データベース型サイトのサイト構造は次のようになります。
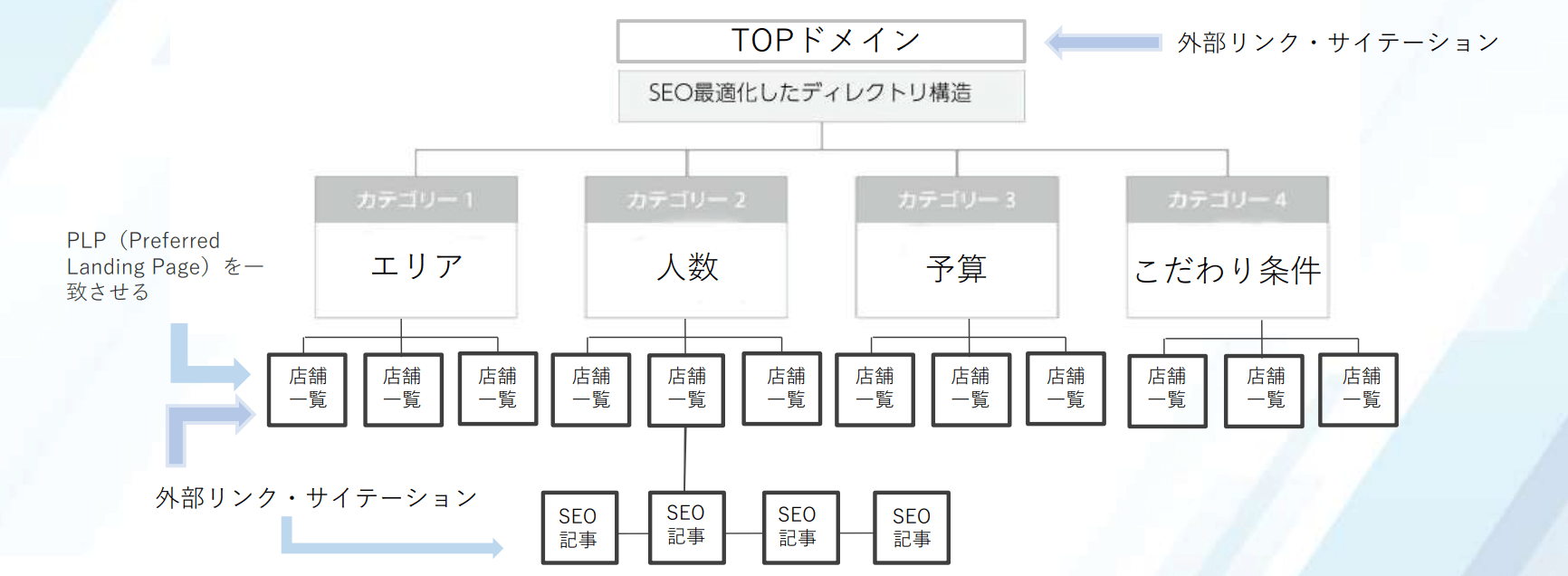
データベース型サイトは、ほぼ例外なく以下の3階層で構成されています。
| 階層 | ページ種別 | 主に対策するキーワード |
|---|---|---|
| ① 第1階層 | トップページ | ビッグキーワード(サービス名・業界名) |
| ② 第2階層 | 一覧ページ(リストページ) 例:エリア×職種、カテゴリ×価格帯 |
ミドル〜ロングテール |
| ③ 第3階層 | 詳細ページ 例:個別商品、個別求人、個別店舗 |
ロングテール・指名検索 |
この3階層は「詳細ページの評価が一覧ページに伝わり、一覧ページの評価がトップに集約される」という評価伝搬の構造を持ちます。詳細ページの品質や内部リンク構造は、一覧ページやトップページの評価形成にも影響しやすいため、詳細ページを軽視するとビッグキーワードで不利になる可能性があります。これは大手データベース型サイトのSEO担当が口を揃えて言う原則です。
データベース型サイトがSEOに強い理由
データベース型サイトが検索結果で他形式より優位に立つ理由は、構造に内在しています。
ロングテールキーワードを「網羅的に」かつ「同時に」取りに行ける
記事型メディアでは1記事1キーワードで地道に積み上げますが、データベース型はキーワードの掛け合わせパターンを一括でページ化できます。
たとえば求人サイトであれば、「エリア(47都道府県×市区町村)×職種(数百種類)×雇用形態×こだわり条件」の掛け合わせで、人が手書きしたら数万年かかる量のページが瞬時に揃います。
専門性と網羅性が同時に成立する
特定ジャンル(不動産・求人・グルメなど)の情報だけを大量に持つため、サイト全体のテーマ性が極めて高くなります。特定ジャンルの情報を体系的に蓄積しやすいため、ユーザーや検索品質評価の観点で専門性・信頼性を示しやすい構造です。ただし、E-E-A-T自体が単独の直接ランキング要因として働くわけではありません。
内部リンクが自然に強固になる
カテゴリ・タグ・関連商品・レコメンドなどでページ同士が自動的に密に繋がるため、クローラーが回遊しやすく、評価が分散しにくい仕組みになっています。
被リンクが受けやすい
「個別店舗ページ」「個別求人ページ」のような指名・実体のあるページは、ブログ・SNS・関連メディアから自然リンクを受けやすく、ドメイン全体の評価が上がります。
データベース型SEOで意識すべき3つの原則
データベース型SEOの戦略は、突き詰めると次の3つに集約されます。
原則①:クロール・インデックスを最適化する
数百万〜数億URLを持つ大規模サイトでは、GoogleがすべてのURLを常にクロール・インデックスするとは限りません。検索エンジンの仕組みは次の4ステップです。
| ステップ | 内容 | 主な対策 |
|---|---|---|
| ① 発見(Discover) | 新しいURLを見つける | 内部リンク・sitemap.xml |
| ② クロール(Crawl) | HTMLを取得して解析 | サーバー応答速度・クロール導線 |
| ③ インデックス(Index) | 登録価値を判断して登録 | 独自性・品質・重複制御 |
| ④ ランキング(Rank) | 順位を決定 | テーママッチ・E-E-A-T・被リンク |
このファネルのどこかで詰まると、コンテンツがどれだけ良くても順位は付きません。コンテンツ品質は主にインデックスやランキングに影響します。一方で、クロールされるためには内部リンク、サイトマップ、サーバー応答速度、URL設計などのテクニカルSEOが重要です。だからこそテクニカルSEOが要となります。
原則②:PLP(Preferred Landing Page)を一致させる
PLPとは、「ある特定のキーワードに対して、サイト運営者が表示させたいページ」を指します。
たとえば「新宿 バイト」というクエリには「新宿のバイト一覧ページ」を表示させたいのに、実際は「新宿×カフェのバイト一覧ページ」が表示されてしまう、というケースが頻発します。これがPLP不一致です。
PLPが一致しないと、
- 順位が上がりにくい(クエリ意図と少しズレる)
- CVRが下がる(ユーザー意図と異なるページに着地)
- 評価が分散する(複数ページで似たキーワードを取り合う=カニバリ)
という三重苦になります。
原則③:ページテンプレート単位で改善する
データベース型サイトでは、改善対象は「ページ」ではなく「テンプレート」です。
「エリア×職種」テンプレートを直せば、「新宿×カフェ」も「池袋×居酒屋」も「渋谷×アパレル」も同時に直ります。逆に、テンプレートが歪んでいるとサイト全体が同時に沈むため、変更は慎重に検証する必要があります。
データベース型SEOの改善プロセス
ここからは実務です。データベース型サイトのSEOは「キーワードカテゴリ × ファネル」の二軸で改善していきます。
| ステップ | 内容 |
|---|---|
| STEP1 | ディレクトリマップとキーワードカテゴリの洗い出し |
| STEP2 | ファネルごとの現状計測(クロール/インデックス/PLP/順位) |
| STEP3 | ファネル別に課題と要因を特定 |
| STEP4 | 優先順位を付けて施策実行 |
| STEP5 | 効果計測と他テンプレートへの横展開 |
STEP1:ディレクトリマップとキーワードカテゴリの洗い出し
まず、サイト内の全URLパターンとキーワードカテゴリの対応表(ディレクトリマップ)を作成します。
| ページテンプレート | URLパターン例 | 対応キーワードカテゴリ |
|---|---|---|
| トップページ | / | サービス名・サイト名(ビッグKW) |
| エリア一覧 | /area/{pref}/ | 「{pref} {サービス}」 |
| 職種一覧 | /job/{job_id}/ | 「{職種} 求人」 |
| エリア×職種 | /area/{pref}/job/{job_id}/ | 「{pref} {職種} 求人」 |
| 詳細ページ | /detail/{id} | 指名検索・固有名詞 |
この時点で、「対策できているが順位が低い」「そもそもテンプレート化されていない美味しいキーワード」が浮き彫りになります。
STEP2:ファネルごとの現状計測
キーワードカテゴリごとに、ファネルの各段階を数値化します。
| ファネル指標 | 取得方法 | 健全な目安 |
|---|---|---|
| クロール状況 | Google Search Console「クロールの統計情報」 | 主要ページ群に偏在 |
| インデックス率 | サイト内検索 site: / GSC「ページ」レポート | インデックス率は、全URLではなく“インデックス対象として設計したURL群”に対して計測します。重要テンプレートや注力カテゴリでは高いインデックス率を目指します。 |
| PLP一致率 | GSC「検索パフォーマンス」でクエリ別ランディングページを確認 | 注力KWで90%以上 |
| 平均掲載順位 | GSC「検索パフォーマンス」 | テンプレ平均で20位以内 |
STEP3:ファネル別に課題と要因を特定
ファネルのどこで詰まっているかを特定し、要因を切り分けます。
| ファネル段階 | 主な要因 |
|---|---|
| クロールされていない | クロールバジェット不足、不要URLへの分散、内部リンク不足 |
| インデックスされていない | noindex設定、低品質判定、重複コンテンツ |
| PLPが一致しない | テーママッチが低い、他ページとカニバリ |
| 目標順位に届かない | ドメイン強度、テンプレ品質、競合優位性 |
STEP4:優先順位を付けて施策実行
すべてを同時には改善できません。次の3軸で優先順位を付けます。
- インパクト:施策対象のキーワードカテゴリの検索ボリューム合計
- 実現可能性:開発工数・関係者の合意難易度
- 再現性:他テンプレートへ横展開できるか
「インパクト×実現可能性」が高いものから着手し、効果を出してから難度の高い施策に進むのが定石です。
STEP5:効果計測と横展開
施策の効果はテンプレート全体で計測します。1ページだけ改善しても、再現性が確認できなければ意味がありません。「テンプレ全体で順位が平均3位上がった」「インデックス率が60%→85%に改善」という形で計測し、効果が出た施策は他テンプレートにも展開します。
ファネル別の具体施策14選
ここからが本記事の中核です。4つのファネルごとに、実務で効いた施策を14個紹介します。
ファネル①:クロールされていない場合の施策(4施策)
施策1:不要URLのクロール制御
クロールバジェットは有限です。並び替え・絞り込み・セッションIDなどの動的パラメータURLが大量にクロールされていると、本当にインデックスしてほしいページに回りません。
| 制御対象 | 制御方法 |
|---|---|
| ソート用パラメータ(?sort=) | robots.txtで Disallow: /*?sort= |
| セッションID付きURL | URLを正規化、Cookieに移行 |
| ファセット検索の組合せURL | 検索結果に表示させたくないURLは noindex、クロール自体を抑制したいURLは robots.txt で制御します。noindex を認識させるにはGooglebotがページをクロールできる必要があるため、noindex 対象ページを robots.txt でブロックしないよう注意します。 |
| 内部検索結果ページ | |
| カート/会員ページ |
施策2:内部リンクの強化と階層の浅層化
クローラーは深い階層を嫌います。主要ページは3クリック以内、できれば2クリック以内でトップから到達できるよう設計します。
具体的には、
- トップページや上位カテゴリから、注力する一覧ページへ直接リンク
- 詳細ページ群から関連する一覧ページへ集約リンク
- フッターやサイドナビでも主要カテゴリへの導線を確保
施策3:XMLサイトマップの最適化
数百万ページのサイトでは、XMLサイトマップを単一ファイルではなく分割し、sitemap_index.xml で束ねるのが基本です。
- ページタイプ別(一覧用、詳細用、コンテンツ用)に分ける
lastmodを正確に出力し、更新頻度をGoogleに伝える- インデックス不要なURL(noindex、canonical統合先など)は載せない
- サイトマップから漏れたページがないか、定期的にdiff検査
施策4:サーバー応答時間(TTFB)の改善
サーバー応答速度が速く安定しているサイトは、Googlebotが効率的にクロールしやすくなります。大規模サイトでは、TTFBの改善がクロール効率の向上につながる可能性があるため、サーバー応答速度の改善は重要です。具体的な改善率を記載する場合は、自社事例や検証データなどの出典を併記しましょう。
- データベースクエリのインデックス追加・N+1問題の解消
- CDNの導入(CloudFront、Fastly、Cloudflareなど)
- 動的ページの結果をキャッシュ層で受ける(Redis/Memcached)
- 画像・JSの遅延読み込み、SVGスプライト化
ファネル②:インデックスされない場合の施策(4施策)
施策5:テンプレートの独自性を上げる(重複率の低下)
データベース型サイトで一番起きやすい落とし穴が「同じテンプレートで作られた数万ページの中身がほぼ同じ」という状態です。Googleは類似ページのほとんどを「クロール済み-インデックス未登録」として登録を見送ります。
独自性を上げる方法:
- 動的サブコンテンツ:そのページ固有の統計情報(例:このエリアの平均給与、この職種の求人数推移)
- 構造化されたユーザー投稿:レビュー、口コミ、Q&Aをテンプレート内に組み込む
- 生成AIによる固有テキスト:ページ固有のデータから一文サマリを動的生成(事実ベースに限る)
- 画像の差別化:プレースホルダ画像ではなく、そのページ固有の画像を確保
施策6:canonicalによる重複コンテンツの制御
ECサイトの色違い商品ページ、求人サイトの掲載期限切れ複製ページなど、構造上避けられない重複は rel="canonical" で正規ページを明示します。
<!-- 商品の色違いページ -->
<link rel="canonical" href="https://example.com/products/123-base">ただし、canonicalは「ヒント」であってGoogleの最終判断ではありません。canonicalが効かない場合は、サブコンテンツや内部リンクで本当に重複なのかを再考する必要があります。
施策7:低品質ページの整理(noindex/削除/統合)
ページが多ければ良いというわけではありません。「在庫切れ詳細ページ」「掲載終了求人」「情報量が極端に少ないカテゴリ」は、低品質と判断されるとサイト全体の評価を下げます。
| ページ状態 | 推奨対応 |
|---|---|
| 短期で復活する可能性 | 一時的に noindex、商品復活時に解除 |
| 恒久的に終了 | 関連カテゴリへ301リダイレクト、または410で明示削除 |
| 情報量が薄いカテゴリ | より上位のカテゴリへ統合 |
| インデックス対象外のページ群 | インデックス対象外にしたいページには noindex を設定します。ただし、noindex ページからの内部リンク評価が常に期待どおり扱われるとは限りません。重要なページへの内部リンクは、インデックス対象ページからも辿れるように設計することが重要です。 |
施策8:詳細ページ→一覧ページの繋ぎ込み強化
一覧ページのインデックスと評価は、配下の詳細ページの品質と数に強く依存します。
- 詳細ページから親カテゴリ・関連カテゴリへのパンくず・リンクを設置
- 一覧ページに表示する詳細ページの件数と表示順を最適化(情報量が薄いと低品質判定)
- 詳細ページのメタタグに、一覧ページの対策キーワードを含める
5-3. ファネル③:PLPが一致しない場合の施策(3施策)
施策9:テーママッチを高めるメタタグ最適化
PLP不一致は「Googleがどのページをそのクエリに当てるか迷っている」状態です。意図したページのテーマ性を強めます。
- Titleの先頭にクエリの主軸ワードを配置
- meta descriptionにクエリの周辺ワードを自然に含める
- H1とTitleを一致させ、ページ目的を明確化
- そのページ固有の固有名詞・数字(件数、エリア名、価格帯)をH1直下に表示
施策10:内部リンクの再配分でカニバリを解消
カニバリ(自社内の複数ページで同じキーワードを取り合う現象)は、PLP不一致の最大の要因です。
- 意図したPLPへのリンクを増やす(アンカーテキストもクエリに合わせる)
- 競合するページからのリンクを減らす、もしくはアンカーテキストを変える
- 場合によっては競合ページを統合またはcanonicalで集約
施策11:詳細ページのレコメンドリンク調整
データベース型サイト特有の問題として、詳細ページから他の詳細ページへのレコメンドが強すぎて、一覧ページに評価が集まらないケースがあります。
レコメンドの一部を「関連する一覧ページ」(例:「この求人と同じエリアの求人一覧」)に振り向けることで、一覧ページの評価を上げられます。
ファネル④:目標順位に届かない場合の施策(3施策)
施策12:サブコンテンツの追加でコンテンツ厚みを増す
メインコンテンツ(商品リスト、求人リストなど)だけでは差別化に限界があります。そのページ固有の有用情報をサブコンテンツとして追加します。
| サイト種別 | 一覧ページに追加するサブコンテンツ例 |
|---|---|
| 求人(エリア×職種) | そのエリアの平均給与、求人数推移、よくある質問、転職体験談 |
| 不動産(エリア) | エリアの治安・交通・教育環境データ、近隣のランドマーク |
| EC(カテゴリ) | カテゴリの選び方ガイド、人気ランキング、比較表 |
| グルメ(エリア×業態) | エリアの最新店舗オープン情報、人気予約時間帯 |
施策13:構造化データの実装
データベース型サイトで効果が大きい構造化データ
| サイト種別 | 推奨スキーマ |
|---|---|
| EC | Product、Offer、AggregateRating、Review、BreadcrumbList |
| 求人 | JobPosting、Organization、BreadcrumbList |
| 不動産 | Place、RealEstateListing(または Product)、PostalAddress |
| グルメ | Restaurant、Menu、Review、AggregateRating |
| イベント | Event、Offer |
| QA/CGM | QAPage、FAQPage |
構造化データによってリッチリザルトに採用されると、検索結果上での視認性が高まり、CTR改善につながる場合があります。ただし、リッチリザルト表示は保証されないため、Search Consoleで実装前後のCTRを検証することが重要です。
施策14:レンダリング方式の見直し(CSR→SSR/ISR)
クライアントサイドレンダリング(CSR)のページは、Googlebotが二段階処理(HTMLレンダリング待ち)で評価するため、インデックスが遅く・不完全になることが知られています。
| レンダリング方式 | データベース型サイトでの推奨度 |
|---|---|
| SSR(サーバーサイド) | ◎ 最も安定 |
| ISR(増分静的再生成、Next.js等) | ◎ 大規模で運用しやすい |
| SSG(完全静的) | ○ 更新頻度が低いなら最強 |
| CSR(クライアントサイド) | CSR自体が必ずSEOに不利というわけではありません。ただし、主要コンテンツ・内部リンク・canonical・構造化データが初期HTMLで確認できない場合、レンダリング依存によってクロールやインデックスの遅延・欠落が起きるリスクがあります。大規模なデータベース型サイトでは、SSRやISRを活用した方が安定しやすいケースがあります。 |
実際、CSRからSSRに切り替えただけでクロール量・インデックス数・流入が3割以上改善した事例が複数報告されています。
2026年に対応すべき新しい論点|LLMO・E-E-A-T・Core Web Vitals
検索体験は2025年以降、生成AI検索(AI Overview、ChatGPT検索、Perplexityなど)の本格普及で大きく変わりました。データベース型サイトもLLMO(Large Language Model Optimization)の視点が不可欠です。
LLMO(生成AI最適化)への対応
生成AIに引用・推奨されるためには、データベース型サイトでは次が効きます。
- 構造化データを徹底実装:LLMはJSON-LDから情報を直接抽出する
- データの一次情報化:自社サイトでしか得られない統計・実数を提示
- エンティティの明確化:会社名・サービス名・著者名をマークアップで明示
- 質問形式の見出し(H2/H3):AIが回答を引きやすい構造に
- 更新日の明示:鮮度の高さがAI引用の決め手になることが多い
E-E-A-Tの強化
データベース型サイトのE-E-A-Tは構造で示すのが要諦です。
- Experience(経験):レビュー・口コミの集積、利用者数の表示
- Expertise(専門性):監修者・専門家プロフィール、業界データの一次情報
- Authoritativeness(権威性):被リンク獲得、メディア掲載歴
- Trustworthiness(信頼性):運営者情報、プライバシーポリシー、SSL、問い合わせ導線
Core Web Vitalsとモバイルファースト
データベース型サイトは画像・JS・データベースクエリが重く、Core Web Vitalsで沈みやすい形式です。次の指標を継続的に監視します。
| 指標 | 目標値 | データベース型サイトでの主な改善策 |
|---|---|---|
| LCP | 2.5秒以内 | 画像のWebP化・遅延読み込み、CDN導入 |
| INP(旧FID) | 200ms以内 | JSの分割読み込み、サードパーティスクリプトの削減 |
| CLS | 0.1以下 | 画像・広告の幅高さ指定、フォント読み込みの安定化 |
| TTFB | 800ms以内 | DBクエリ最適化、キャッシュ層、サーバースペック |
データベース型サイトでよくある3つの落とし穴と回避策
落とし穴①:パラメータURLの組合せ
ファセット検索(複数条件で絞り込み)を導入すると、条件の組合せで数万〜数百万URLが自動生成されることがあります。
/search?area=tokyo&job=engineer&salary=400-500&type=full
/search?area=tokyo&salary=400-500&job=engineer&type=full ← 並び違いで別URL扱い回避策:
- パラメータの順序を正規化する(サーバー側で並びを統一)
- 価値のない組合せは
noindex+nofollow+robots.txtで制御方法を分ける - 価値のある組合せだけ静的URLに昇格(SEOフレンドリーURL化)
落とし穴②:動的URLのまま放置
× /products.php?id=12345&color=red
○ /products/12345/red動的URLでも検索エンジンは読めますが、「同じページが複数URLでアクセス可能」「パラメータ順違いで重複」という問題が起きやすく、リライト(mod_rewriteなど)で静的URL化するのが定石です。
# Apacheの.htaccess例
RewriteEngine On
RewriteRule ^products/([0-9]+)/?$ /product-display.php?productid=$1 [L,QSA]落とし穴③:突然の順位下落=サイト全体のテンプレ問題
データベース型サイトで「ある日突然、サイト全体のキーワードが軒並み下がる」ことがあります。これは個別ページの問題ではなく、テンプレート単位の問題です。
確認すべきポイント:
- テンプレートに最近変更(HTML構造、CSS、JS)が入っていないか
- noindexやcanonicalが意図せず全ページに付与されていないか
- robots.txtで誤ってクロールブロックしていないか
- サーバーのレスポンス時間が急激に悪化していないか
- 重複コンテンツとして大量にインデックスから除外されていないか
GSCの「ページ」レポートと「Core Web Vitals」レポート、そして開発のChangelogを並べて時系列で確認すれば、ほぼ原因にたどり着けます。
データベース型SEOの効果を測る指標
データベース型サイトのSEO担当者が定常的に追う指標は次の通りです。
| 指標カテゴリ | 具体指標 | 確認場所 |
|---|---|---|
| クロール | クロールリクエスト数、平均応答時間、クロール対象別の内訳 | GSC「クロールの統計情報」 |
| インデックス | インデックス済み数、クロール済み-インデックス未登録数、除外理由別件数 | GSC「ページ」レポート |
| PLP一致 | テンプレ別注力KW群でのPLP一致率 | GSC「検索パフォーマンス」 |
| 順位 | テンプレ別の平均掲載順位、TOP3/TOP10内のKW数 | GSC、順位計測ツール |
| 流入 | テンプレ別オーガニックセッション数、CVR、CV数 | GA4、内部解析 |
| Core Web Vitals | LCP/INP/CLSの良好率 | GSC「ウェブに関する主な指標」、PSI |
| ドメイン強度 | リファラルドメイン数、被リンク総数、指名検索ボリューム | Ahrefs、Search Console |
これらをテンプレート単位×時系列でダッシュボード化しておくと、改善の効果と異常の早期検知の両方ができます。
まとめ
データベース型サイトのSEOは、記事型メディアとはまったく別物の世界です。1記事を磨き込んで順位を上げていく従来のアプローチではなく、サイト構造そのものを設計し直すことで、数万・数十万ページを同時に動かしていく取り組みになります。
まず押さえておきたいのは、改善の単位が「ページ」ではなく「テンプレート」であるということです。1ページずつ手を入れても全体は変わりませんが、テンプレートを一つ最適化すれば、そこから生成される数万ページが一斉に良くなります。この発想の転換が、データベース型SEOの出発点です。
次に重要なのが、「キーワードカテゴリ × ファネル」という二軸で課題を切り分ける視点です。どのキーワード群が、クロール・インデックス・PLP・順位のどの段階で詰まっているのか。これを冷静に分解できるかどうかで、施策の精度がまったく変わります。やみくもにコンテンツを増やしたり、闇雲にリンクを張り替えたりしても成果には繋がりません。
そして、土台となるのはあくまでテクニカルSEOです。クロール導線の設計、URLの整理、構造化データの実装、サーバー性能の改善。これらが整って初めて、コンテンツSEOが効いてきます。順序を逆にすると、いくら良いコンテンツを作っても評価が積み上がりません。
最後に意識したいのは、施策に再現性を持たせて横展開することです。一つのテンプレートで効果が確認できた施策は、他のテンプレートにも展開できます。この積み重ねこそが、サイト全体を底上げしていく王道です。
データベース型サイトのSEOは専門性が高く、成果が出るまで時間もかかります。しかし、いったん仕組みが回り始めると、テンプレートを一つ直しただけで数十万ページ分の順位が一気に動くという、記事型メディアでは決して起こらないダイナミックなインパクトを生み出します。短期では地味でも、中長期では爆発力を持つ。これがデータベース型SEOの面白さです。
東京SEOメーカーでは、データベース型サイトのSEOコンサルティングを数多くお手伝いしてきました。クロール・インデックスの設計から、テンプレート単位での課題分析、開発要件の整理まで一気通貫でご支援できます。「何から手を付ければよいか分からない」「施策の優先順位が決められない」「成果が出ずに停滞している」といったお悩みがありましたら、お気軽にご相談ください。


















